
How AI Lecture Video Technology Actually Works: A Technical Deep Dive
Jun 1, 2026 | By Team SR

AI-generated lecture videos have moved from novelty to mainstream adoption faster than most EdTech innovations. Universities, corporate training departments, and online course platforms are producing thousands of AI-generated videos monthly. But for technology professionals and educators evaluating these tools, a critical question often goes unanswered: how does the underlying technology actually work?
 Follow us
Follow us Follow us
Follow usThis article provides a technical breakdown of the AI systems that power modern lecture video generation, examining each component of the pipeline from document parsing to final video output. Understanding these mechanisms helps you make better decisions about which tools to adopt and how to optimize your content for the best results.
The End-to-End Pipeline
AI lecture video generation is not a single model or algorithm. It is a pipeline of specialized AI systems working in sequence, each handling a distinct task. The major stages are document understanding, content structuring, script generation, visual scene composition, speech synthesis, avatar animation, and final video rendering.
Stage 1: Document Understanding
The pipeline begins when a user uploads a source document — typically a PDF, DOCX, PPTX, or plain text file. The document understanding module parses the file to extract text content, identify structural elements (headings, paragraphs, lists, tables), and preserve the hierarchical relationships between sections.
RECOMMENDED FOR YOU
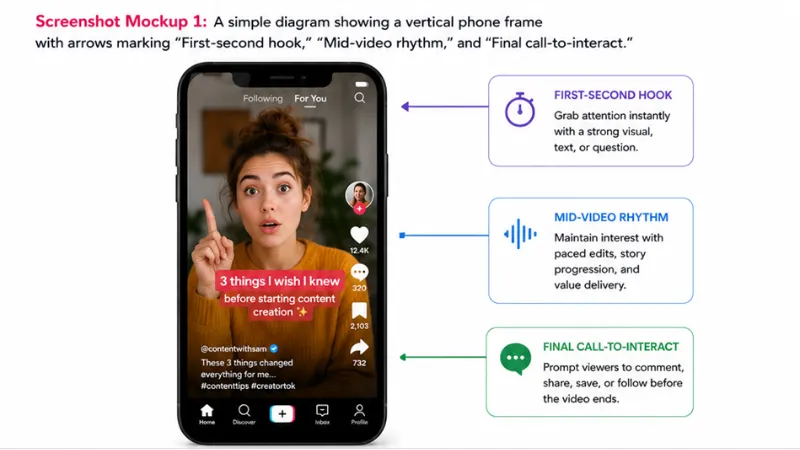


For PowerPoint files, this stage also captures visual layout information: where text boxes and images are positioned on each slide, what the visual hierarchy implies about content importance, and any speaker notes embedded in the file. This visual metadata provides additional context that improves downstream content structuring.
The technical challenge here is handling the diversity of document formats and layouts. A well-structured academic paper with clear section headings is straightforward to parse. A marketing PDF with non-standard layouts, embedded graphics, and text in image format requires more sophisticated extraction. Modern systems use a combination of rule-based parsing for structured formats and computer vision techniques for less structured documents.
Stage 2: Content Structuring and Segmentation
Raw extracted text needs to be organized into logical video segments. This is where natural language processing models analyze the content to identify topic boundaries, determine which concepts are primary versus supporting, and create a proposed video structure.
The segmentation model considers several factors: semantic coherence (keeping related concepts together), optimal segment length (targeting 30-90 seconds per scene for educational content), and narrative flow (ensuring segments build on each other in a logical sequence). The output is a structured outline where each entry represents one scene in the final video.
Stage 3: Script Generation
The script generation stage transforms the segmented content into narration scripts. This is arguably the most sophisticated component of the pipeline, requiring the AI to generate text that sounds natural when spoken aloud, accurately represents the source material, and follows pedagogical best practices.
Modern script generators use large language models fine-tuned specifically for educational narration. These models have been trained not just on general text but on thousands of examples of effective instructional scripts. They understand that educational narration should define new terms before using them, signal topic transitions explicitly, vary sentence length and structure to maintain listener engagement, and summarize key points at the end of each major section.
Advanced platforms like the AI tool for educational video lectures from Leadde.ai allow users to specify parameters like tone (formal, conversational, analytical), detail level (summary, balanced, comprehensive), and audience context — all of which influence the script generation model's output.
The Visual and Audio Components
Stage 4: Visual Scene Composition
Each script segment needs a corresponding visual scene. The scene composition module determines the layout for each video frame: where the AI presenter appears, how text elements are displayed, what supporting images or graphics are included, and how visual transitions are handled.
This stage draws from multiple sources for visual content. Text elements are extracted directly from the script and displayed as on-screen highlights for key terms, definitions, or data points. Supporting images can come from the platform's built-in media library, from AI image generation models that create custom visuals based on the script content, or from user-uploaded assets.
The layout engine uses design principles encoded as rules and learned patterns: visual balance, appropriate text density for video (less than for print), color contrast for readability, and spatial relationships between the presenter and content elements.
Stage 5: Speech Synthesis (Text-to-Speech)
The narration script is converted to audio using neural text-to-speech (TTS) models. Modern TTS has advanced significantly beyond the robotic voices of earlier generations. Current systems produce speech that is difficult to distinguish from human narration in blind listening tests.
High-quality TTS for educational content requires more than just natural-sounding speech. It needs appropriate pacing — slower for complex concepts, faster for transitions. It needs correct emphasis — stressing key terms and placing appropriate pauses at structural boundaries. It needs consistent tone throughout — maintaining the specified formality level and speaking style across potentially long scripts.
Multilingual TTS is a particular technical strength of some platforms, supporting dozens of languages with multiple regional dialects. The challenge is not just pronunciation but prosody — the rhythm, stress, and intonation patterns that vary across languages and dialects. Training separate prosody models for each language variant produces more natural results than a one-size-fits-all approach.
Stage 6: Avatar Animation
The AI avatar — the digital presenter who appears on screen — is driven by a combination of lip-sync generation, expression inference, and body motion synthesis.
Lip-sync maps the audio waveform to mouth movements (visemes) in real-time, ensuring that the avatar's lips match the spoken words. Modern systems achieve frame-accurate lip-sync that is indistinguishable from live footage at standard video resolution.
Expression inference is where the latest generation of avatar technology distinguishes itself. Rather than using a fixed set of expressions mapped to keywords, advanced expression engines analyze the semantic and emotional content of each narration segment and generate appropriate facial expressions, head movements, and gestures. When the script presents surprising data, the avatar shows a subtle expression of surprise. When emphasizing a key point, the avatar may lean forward slightly or use a hand gesture for emphasis.
The most advanced systems, like the Expressive IV Engine, perform full-body motion synthesis — generating natural upper-body movements including shoulder shifts, hand gestures, and postural changes that complement the verbal delivery.
Quality and Performance Considerations
Accuracy of Content Interpretation
The primary quality risk in AI lecture video generation is content misinterpretation. The AI might emphasize the wrong points, miss nuances in technical content, or generate scripts that are factually correct but pedagogically suboptimal. This is why the human review step — where the creator reviews and refines the AI-generated script before final production — is critical rather than optional.
Processing Speed and Scalability
Processing time varies by document length and platform architecture. Most modern platforms can process a 10-page document and generate a complete video in under 10 minutes. The primary bottleneck is typically the avatar animation rendering, which is computationally intensive. Cloud-based architectures distribute this computation across GPU clusters, enabling parallel processing of multiple videos.
Output Quality vs. Source Quality
The relationship between input and output quality follows a clear pattern: well-structured documents with clear headings, logical flow, and concise writing produce significantly better videos than unstructured text dumps. Investing time in document preparation yields disproportionate returns in output quality.
The Technical Trajectory
Several technical trends will shape the next generation of AI lecture video tools. Multimodal understanding — models that can interpret images, charts, and diagrams within documents, not just text — will improve visual scene composition. Adaptive content generation — AI that adjusts the complexity and pacing based on individual viewer behavior — will personalize the learning experience. Real-time interaction — viewers engaging in dialogue with the AI presenter during playback — will transform passive video into active learning environments.
For technology professionals evaluating AI lecture video tools, the key insight is that this is a pipeline technology where each stage contributes to the final quality. The best platforms invest in optimizing every stage — not just the most visible ones like avatar quality — and provide users with control points throughout the pipeline where human judgment can refine the AI's output.
Recommended Stories for You

Team SR Feb 14, 2026


The Peace of Mind Roadmap: How Full-Coverage Insurance Safely Protects Your Hard-Earned Assets
Oliver Bennett Jun 20, 2026


Team SR May 28, 2026

Team SR Apr 14, 2026
Trending Stories

Why the World Cup Is So Important for Young Talents

Guest Post Marketplace Trends Every SEO Agency Should Watch

How Investor Due Diligence Is Changing as Privacy Becomes Critical for VCs

Ecommerce CRO Best Practices Every Online Business Should Follow
The Best Forex Trading Platforms for Beginners in 2026

Which dental clinic abroad is the best in Istanbul, Turkey?

How Smarter Building Systems Are Improving Modern Residential Comfort

7 Signs You’ve Partnered with the Wrong Software Development Firm – And What to Do Instead