
Building Scalable SaaS Applications: Key Lessons from High-Growth Startups
Jun 8, 2026 | By Team SR

Most SaaS founders hit the same wall. The product launches, early customers come in, traction builds, and then something unexpected happens: the system starts straining under the weight of its own success. Pages slow down. Deployments become risky. Customer data gets harder to isolate. What felt like a functional architecture at 200 users turns brittle at 2,000.
 Follow us
Follow us Follow us
Follow usThat gap between building software and building software that actually scales is where a lot of promising SaaS companies quietly stumble. The good news is it's predictable. And the high-growth teams that get it right aren't operating on secret knowledge. They're applying a set of decisions early that most teams delay until the problems become unavoidable.
This article covers six of those decisions. Each one is grounded in patterns we've seen across successful SaaS application development projects, common failure modes in early-stage teams, and what the research tells us about where scalability breaks down in practice.
Why Scalability Is the Foundation of Long-Term SaaS Success
Scalability in SaaS isn't a nice-to-have architectural feature. It's a revenue decision. A platform that can't handle growing demand doesn't just slow down; it actively loses customers, damages trust, and eventually forces expensive rebuilds that pull engineering focus away from the product itself.
RECOMMENDED FOR YOU



The numbers here are hard to ignore. Gartner data shows that by 2026, global public cloud spending is projected to surpass $800 billion, driven in large part by the scaling demands of SaaS platforms. Yet most startups still treat architecture as an afterthought, right up until a performance failure makes it impossible to ignore.
53%
users abandon an app if it takes more than 3 seconds to load.
Source: Google Analytics benchmark data
For SaaS applications specifically, speed and reliability aren't just UX concerns. They're directly tied to retention. Industry data shows that a 5% improvement in retention can increase profits by up to 95%. If slow performance or downtime is contributing to churn, the business impact compounds fast.
Scalability affects customer experience, revenue growth, and operational efficiency all at once. That's why it belongs in the foundation, not the roadmap.
Lesson #1: Architect for Tomorrow, Not Just Today
Avoid Building Around Current User Volume
One of the most consistent mistakes in early SaaS development is designing a system around today's usage. It feels practical. You don't over-engineer. You ship faster. But the trap is that architectural decisions made at 500 users tend to become blockers at 50,000.
Tight database coupling, monolithic deployment units, hardcoded environment assumptions, and skipped abstraction layers all feel fine early on. They become serious problems when you're trying to serve enterprise clients, onboard dozens of new accounts per week, or handle usage spikes from a product launch.
The Importance of Flexible System Design
Flexible design doesn't mean over-engineering everything upfront. It means making decisions that can evolve without requiring a full rewrite. A modular monolith, for instance, gives you the organizational clarity of microservices without the operational complexity until you actually need it. API-first architecture keeps your integrations clean and your frontend decoupled from business logic.
Key Insight
Successful SaaS companies design systems that can evolve without major rebuilding efforts. The decision points that matter most aren't about which framework to use; they're about how tightly coupled your core services are and whether your data model can handle schema changes without taking the whole system offline.
When Startups Outgrow Their Initial Architecture
The most expensive architectural rebuilds happen when companies are growing fast and can't afford the downtime or engineering focus to do it properly. Planning for change from the start is significantly cheaper than reacting to it under pressure.
Actionable Takeaway
- Separate concerns early: UI, business logic, and data access should never be deeply entangled
- Use environment configuration, not hardcoded values, everywhere from day one
- Design your data model to support multi-tenancy, even before you have multiple tenants
Lesson #2: Embrace Cloud-Native Infrastructure Early
The Scalability Benefits of Cloud Platforms
Cloud-native infrastructure gives SaaS teams something that on-premise or semi-cloud setups simply can't: the ability to scale resources in response to real demand rather than predicted demand. Auto-scaling groups, managed Kubernetes clusters, serverless functions, and CDN layers let you right-size infrastructure dynamically without manual intervention.
This matters practically. A B2B SaaS platform that goes viral after a Product Hunt launch or lands a large enterprise client shouldn't require a weekend of manual infrastructure work to stay online. Cloud-native design makes that kind of response automatic.
Managing Traffic Spikes Efficiently
Traffic spikes are never perfectly predictable. A new feature announcement, a press mention, or a partner integration can all create sudden load increases. Systems that rely on fixed capacity fail in these moments. Cloud infrastructure, properly configured, absorbs them.
That said, cloud-native doesn't mean expensive by default. Done right, it means your costs are aligned with usage rather than reserved ahead of time for capacity you might not need.
Reducing Operational Complexity
Managed services for databases, caching, and message queuing reduce the operational overhead that typically slows down small teams. Instead of maintaining your own Redis cluster or PostgreSQL replication setup, you use a managed provider and redirect that engineering time toward product work. It's a practical trade-off, and most high-growth SaaS teams make it early.
Lesson #3: Performance Is a Growth Strategy
Why Speed Directly Impacts Retention
Application speed isn't a technical metric; it's a business metric. Users form opinions about software quality in milliseconds. A slow dashboard, a sluggish report load, or an unresponsive search function doesn't just frustrate users. It erodes trust in the product itself.
For SaaS specifically, where customers are paying a recurring fee and comparing you to alternatives regularly, performance problems are a quiet churn driver. They don't show up in cancellation surveys as "your app was slow." They show up as "we found something that better meets our needs."
Common Performance Bottlenecks
Most SaaS performance issues trace back to a handful of recurring causes: N+1 database query problems, missing cache layers for frequently read data, synchronous processing for tasks that should be asynchronous, and over-fetching data in API responses.
None of these are exotic problems. They're all solvable early, when the codebase is small and the fixes are simple. Retrofit them at scale and you're looking at significant refactoring work under production pressure.
Monitoring Before Problems Become Visible
The worst time to learn about a performance problem is when a customer reports it. By then, you've already lost something: either their trust, their session, or in some cases, their renewal. Proactive monitoring with tools like Datadog, New Relic, or open-source observability stacks lets you catch degradation trends before they become incidents.
Set baselines early. If you don't know what "normal" looks like, you can't detect when something shifts.
Lesson #4: Build Security Into the Foundation
Security as a Growth Enabler
Security is usually framed as a protection layer. In SaaS, it's also a sales asset. Enterprise buyers ask about SOC 2 compliance, data encryption, audit logging, and role-based access control before they sign a contract. If your architecture can't support those requirements, you're locked out of those deals.
Protecting Customer Trust at Scale
A single data breach or a serious security incident can undo months of growth. The reputational damage in SaaS is particularly lasting because customers are entrusting you with their operational data. Data isolation in multi-tenant environments, proper secret management, and thorough input validation aren't optional extras. They're table stakes.
Key Insight
Security becomes significantly harder and more expensive when added as a retrofit. A permissions model bolted onto an existing codebase requires touching nearly every data access layer. Designed upfront, it's a few days of architecture work. Added later, it can take months.
Preparing for Compliance Requirements
GDPR, HIPAA, SOC 2, ISO 27001: the compliance landscape varies by market and customer segment, but the structural requirements overlap considerably. Audit trails, data deletion workflows, encryption at rest and in transit, and access logs. Teams that account for these requirements in their initial custom software development architecture handle compliance certifications without major disruption later. Teams that don't typically face a painful refactor.
Lesson #5: Design Around Customer Growth
Flexible User and Account Management
SaaS platforms evolve. A product that starts serving individual users often needs to support teams, organizations, sub-accounts, and enterprise hierarchies as it matures. If your user and account model was designed for a single user per account, adding multi-user team support later is a significant data and logic migration.
Build account structure flexibility early. It costs little when the data model is clean and the user base is small. It costs a lot when you're trying to migrate active production data while keeping the system live.
Scalable Billing and Subscription Models
Billing logic is frequently underestimated. Usage-based pricing, tiered plans, seat-based billing, annual versus monthly commitments, trial periods, discount codes, and enterprise custom contracts: the combinations multiply fast. Systems that hardcode billing logic end up requiring developer time for every pricing change, which slows down a core business lever.
Dedicated billing infrastructure, whether built on Stripe, Chargebee, or a custom layer, keeps pricing logic cleanly separated from product logic. That separation matters more as the business grows.
Supporting Enterprise Requirements
Enterprise contracts often come with specific technical requirements: SSO via SAML or OIDC, custom data retention periods, dedicated infrastructure options, SLA guarantees, and security reviews. SaaS platforms that can't accommodate these requirements can't close enterprise deals, regardless of how good the product is. Plan for the customer segment you want to serve 18 months from now, not just the one you have today.
Lesson #6: Automation Creates Operational Scale
Automated Testing
Manual testing at scale doesn't work. It slows release cycles, introduces inconsistency, and creates a culture of fear around deployments. A solid test suite, unit tests for core logic, integration tests for critical paths, and end-to-end coverage for key user flows, removes the bottleneck.
The teams shipping daily or multiple times per day aren't taking more risk. They're automating the verification that things work, which actually reduces risk while increasing velocity.
Continuous Deployment Practices
CI/CD pipelines are standard practice for high-growth SaaS teams, but the quality of implementation varies enormously. A pipeline that runs tests, checks code quality, builds artifacts, and deploys to staging automatically is very different from a pipeline that just runs unit tests and calls it done. Invest in making deployment safe and fast. It's a multiplier on everything else the team does.
Infrastructure Automation
Infrastructure as code with tools like Terraform or Pulumi means your environments are reproducible, version-controlled, and auditable. It also means new environments for staging, load testing, or new regions can be spun up in minutes rather than days. That capability directly supports scaling operations.
Operational Monitoring
Automated alerting, anomaly detection, and runbook automation keep your on-call burden manageable as the system scales. The goal isn't to eliminate human judgment from operations; it's to make sure humans are applying their judgment to the things that actually need it, not responding to noise or performing repetitive checks manually.
Key Insight
The fastest-growing SaaS companies automate repetitive processes before they become bottlenecks. When scaling from 100 to 10,000 customers, the operational work doesn't scale linearly if automation is in place. Without it, engineering teams get consumed by maintenance rather than product work.
What High-Growth SaaS Startups Have in Common
Across successful SaaS teams, a few consistent patterns stand out: a scalability-first mindset from the start, decisions driven by usage data rather than assumptions, continuous optimization instead of big-bang rewrites, a strong engineering culture around code quality and testing, and a product that evolves in direct response to how customers actually use it.
The contrast with reactive teams is instructive.
Reactive SaaS Teams Scalable SaaS Teams Fix performance issues after customers complain Monitor proactively and catch degradation early Add security features when compliance is required Design security into the foundation from the start Manual deployment processes with inconsistent results Automated CI/CD pipelines with reliable, fast releases Build around today's user volume and account structure Design for the customer segment they want in 18 months Billing logic embedded in product code Dedicated billing infrastructure, cleanly separated Infrastructure managed manually per environment Infrastructure as code, reproducible and version-controlled
A Practical Scalability Checklist for SaaS Leaders
Before committing to a production architecture or evaluating your current system's readiness, run through these checkpoints.
- Architecture: Are your services loosely coupled? Can one component be updated or scaled without redeploying the entire system?
- Infrastructure scalability: Can your infrastructure auto-scale in response to real demand without manual intervention?
- Database performance: Have you addressed indexing, query optimization, and connection pooling? Do you have a caching layer for frequently read data?
- Security posture: Is data isolation enforced at the database level for multi-tenant accounts? Are secrets managed outside the codebase?
- Monitoring capabilities: Do you have baseline performance metrics, alerting thresholds, and error tracking in place before problems occur?
- Automation maturity: Are deployments fully automated? Do you have test coverage on critical paths? Is infrastructure managed as code?
- Customer growth readiness: Can your account model support teams, organizations, and enterprise structures without schema migrations under pressure?
Not every box needs to be checked before launch. But every unchecked item is a known risk. Teams that acknowledge those risks and plan for them make better sequencing decisions than teams that discover them under production pressure.
Final Thoughts
Scalability is a business strategy. Not just a technical one. The decisions made during the earliest stages of a SaaS product's MVP and development phase determine how much the platform costs to operate at scale, how quickly the team can ship, and which customer segments the product can realistically serve.
High-growth SaaS startups share a mindset: they treat scalability as a first-class concern from day one, not a project for later. They don't over-engineer. But they do make architectural choices that leave room to grow without paying back a painful technical debt bill when the growth actually arrives.
The six lessons here aren't theoretical. They're patterns drawn from what works and, frankly, from a lot of expensive mistakes that didn't need to happen. Whether you're building something new or assessing an existing platform's readiness to scale, the checklist above is a reasonable starting point. The infrastructure choices, the architecture decisions, the automation investments: all of it compounds. Start earlier than you think you need to.
Frequently Asked Questions
What makes SaaS applications scalable?
Scalable SaaS applications are built on flexible architecture patterns like microservices or modular monoliths, cloud-native infrastructure, automated deployment pipelines, and database designs that handle growing data volumes without requiring full system rewrites. The key isn't any single technology choice; it's how loosely coupled the components are and how much change can be absorbed without cascading rework.
When should startups start planning for scalability?
From day one, ideally. The costliest mistake most early-stage teams make is treating scalability as a future problem. Architectural decisions made during the MVP stage directly affect how difficult and expensive it is to scale later. You don't need to over-engineer everything upfront, but you do need to make choices that don't box you in.
What are the biggest scalability challenges in SaaS development?
The most common challenges include database bottlenecks at scale, tight coupling between services that makes individual components hard to update independently, inadequate monitoring before problems surface, lack of automation in deployment and testing, and security gaps that become harder to retrofit later. Most of these are easier to address early than to fix under production pressure.
How does cloud infrastructure improve SaaS scalability?
Cloud infrastructure allows SaaS teams to scale resources up or down based on demand without major upfront investment. Auto-scaling groups, managed databases, CDNs, and serverless functions all help handle traffic spikes efficiently while keeping costs aligned with actual usage. The operational benefit is equally significant: managed services reduce the maintenance overhead that would otherwise consume engineering time.
Why is automation important for SaaS growth?
Automation removes the human bottlenecks that slow down growing teams. Automated testing catches regressions early, CI/CD pipelines reduce deployment risk and increase release frequency, infrastructure-as-code makes environment management repeatable and auditable, and automated monitoring means your team isn't discovering problems after customers do. At scale, the compounding effect of automation on team efficiency is substantial.
Building a SaaS Product That Needs to Scale?
Elsner's development team has built and scaled SaaS platforms across industries. From architecture consulting to full-cycle product development, we help founders and product teams make the right decisions early.
Recommended Stories for You

Team SR Feb 7, 2026

Team SR Jan 28, 2026

Team SR Jun 2, 2026

Team SR Dec 22, 2025

Team SR Jul 8, 2026

Team SR Nov 14, 2025
Trending Stories

The Role of HR in Aligning Leadership Decisions With Employee Reality

The US Engineering Credential European Deep Tech Founders Are Picking Up
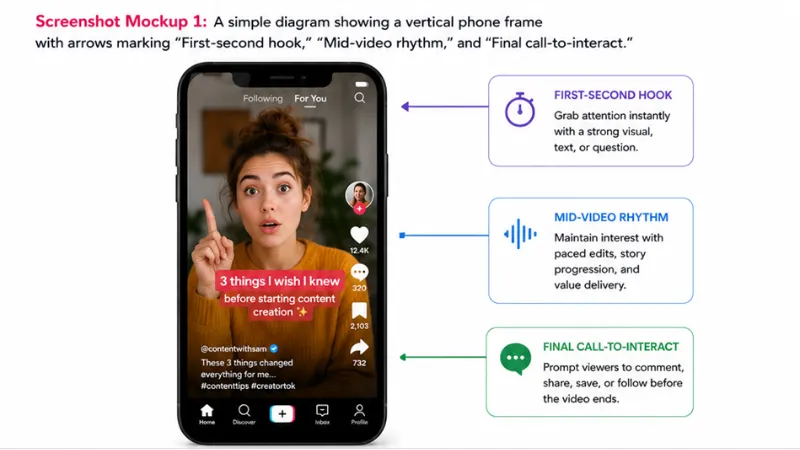
Crafting Positive Momentum on TikTok via Improved Interaction Habits

iGaming License: Meaning, Importance, and Its Role in the Global Online Gaming Industry

How to Find the Best Online Reputation Management Services When Everyone Claims to Be the Best
The Best Forex Trading Platforms for Beginners in 2026

Turning Complex Challenges into Clear Opportunities

Why Hiring Readiness Matters More Than Ever for Fast-Growing Startups